Week 5 - Dunemaxxing
April 2024 (7277 Words, 41 Minutes)
This week, I participated in University of Maryland’s UMDCTF with BYU Cyberia. I only ended up solving one challenge, but it introduced to me a whole new category of CTF challenges: attacking machine learning models.
Attack of the Worm
the fremen are trying to sabotage the spice harvest and they need your help! spice harvesters have worm image recognition technology to know when to avoid a worm attack. luckily for you, a hacker genius got access to the pixels of the worm image, but you can only change up to 30 pixels of it. can you help the fremen destroy a spice harvester?
NOTE: the model is the same as `the worm strikes back`
`nc challs.umdctf.io 31774`
I’ve been a fan of dune since I was 14, so I’ll always make sure to help the Fremen when I can. We are given three files:
- model.pt
- server.py
- worm.png
I only had a theoretical understanding of AI/ML, mostly gleaned from Sebastian Lague’s video entitled “How to Create a Neural Network (and Train it to Identify Doodles) and “But What is a Neural Network” from 3Blue1Brown, 2 channels who are guilty of getting me into Computer Science back in high school.
model.pt: It looks like a .pt file is generated by pytorch, which is an ML Python library. I’d imagine this contains some kind of model.
worm.png: A 224x224 pixel PNG file:

server.py: A lot of interesting things happen here, so let’s break it down:
#!/usr/local/bin/python
import sys
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
from torchvision.models import resnet18
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 1)
model.load_state_dict(torch.load('model.pt'))
original = np.array(Image.open("worm.png"))
modified = original.copy()
inp = input(f"Enter a list of pixels to change, in the format 'x,y,r,g,b;x,y,r,g,b;...':\n")
try:
pixels = inp.split(";")
assert len(pixels) <= 30
for pixel in pixels:
x, y, r, g, b = map(int, pixel.split(","))
modified[y, x] = [r, g, b]
except:
print("Too many pixel changes.")
sys.exit(0)
# Reorder by channel
x = torch.tensor(modified.transpose(2, 0, 1) / 255.0, dtype=torch.float32).unsqueeze(0)
with torch.no_grad():
y = torch.sigmoid(model(x))
print(y)
if y >= 0.5:
print("that's clearly a worm buddy")
sys.exit(0)
with open("flag.txt", "r") as f:
print("LISAN AL GAIB")
print(f.read())
Starting with the first few lines:
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 1)
model.load_state_dict(torch.load('model.pt'))
It looks like it creates a resnet18 object called model, then loads the actual state of the model from model.pt. The next bit of code is a little bit more complex:
original = np.array(Image.open("worm.png"))
modified = original.copy()
inp = input(f"Enter a list of pixels to change, in the format 'x,y,r,g,b;x,y,r,g,b;...':\n")
try:
pixels = inp.split(";")
assert len(pixels) <= 30
for pixel in pixels:
x, y, r, g, b = map(int, pixel.split(","))
modified[y, x] = [r, g, b]
except:
print("Too many pixel changes.")
sys.exit(0)
It takes the file worm.png and turns it into a numpy array, then creates a copy called modified. It then takes a string with format x,y,r,g,b;x,y... for 30 pixels worth of data. It will then set those 30 pixels to whatever color value we assign. The next chunk is where we actually use the pretrained model given to us:
x = torch.tensor(modified.transpose(2, 0, 1) / 255.0, dtype=torch.float32).unsqueeze(0)
with torch.no_grad():
y = torch.sigmoid(model(x))
print(y)
if y >= 0.5:
print("that's clearly a worm buddy")
sys.exit(0)
with open("flag.txt", "r") as f:
print("LISAN AL GAIB")
print(f.read())
After some reading, it looks like the script creates a tensor, a multidimensional array, called x out of the modified image. It then passes the tensor through the model, and scores it as a variable y on a typical sigmoid activation function. It looks like our goal is to push that score y down past 0.5. Luckily, models are deterministic, so there is no randomness involved from the challenge.
Also, I’m not sure what’s going on with the modified.transpose(2,0,1). I’m assuming that’s just Bene Gesserit witchery, and is not vital to this challenge.
Our goal is to generate a series of up to 30 pixel alterations that will trick the model into not recognizing the image as a worm. Seems simple enough. I figured this challenge would take me a while, so I created an intentionally naive implementation to run in the background while I built a more intelligent solution.
This script randomly generates pixels to change, and if the score is lower than the lowest on record, it prints out the score and the input values:
#!/usr/local/bin/python
import sys
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
from torchvision.models import resnet18
from random import randint
def random_gen():
x = randint(0, 223)
y = randint(0, 223)
r = randint(0, 255)
g = randint(0, 255)
b = randint(0, 255)
return (x, y, r, g, b)
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 1)
model.load_state_dict(torch.load('model.pt'))
original = np.array(Image.open("worm.png"))
lowest = 1
while True:
modified = original.copy()
mods = [random_gen() for _ in range(30)]
for mod in mods:
x, y = mod[0], mod[1]
r, g, b = mod[2], mod[3], mod[4]
modified[y, x] = [r, g, b]
x = torch.tensor(modified.transpose(2, 0, 1) / 255.0, dtype=torch.float32).unsqueeze(0)
with torch.no_grad():
y = torch.sigmoid(model(x))
if y < lowest:
lowest = y
print(f"New lowest: {y} | {mods}")
if y < 0.5:
print(mods)
break
with open("res.txt", "a+") as f:
elems = ";".join(','.join(map(str, mod)) for mod in mods)
f.writeline(elems)
x = torch.tensor(original.transpose(2, 0, 1) / 255.0, dtype=torch.float32).unsqueeze(0)
with torch.no_grad():
y = torch.sigmoid(model(x))
print(y)
Here’s what it looks like running for about a minute on my machine:
➜ attack_of_the_worm python3 attack.py
New lowest: tensor([[0.5726]]) | [(160, 27, 79, 122, 177), (97, 221, 13, 170, 139), (40, 158, 189, 22, 186), (95, 105, 0, 222, 106), (145, 5, 34, 173, 234), (155, 3, 196, 57, 29), (51, 42, 137, 161, 249), (125, 41, 245, 121, 112), (74, 22, 121, 61, 235), (6, 157, 148, 183, 211), (45, 127, 41, 129, 19), (85, 67, 5, 91, 218), (22, 187, 187, 255, 50), (103, 21, 219, 204, 160), (35, 199, 70, 247, 29), (187, 203, 93, 219, 21), (168, 137, 31, 239, 179), (173, 68, 32, 40, 208), (123, 185, 205, 3, 172), (187, 91, 4, 193, 51), (209, 10, 196, 216, 130), (81, 162, 111, 99, 240), (176, 48, 174, 162, 235), (7, 213, 226, 113, 4), (20, 90, 132, 14, 119), (163, 103, 216, 99, 47), (0, 189, 109, 9, 60), (70, 154, 209, 58, 33), (175, 148, 180, 206, 169), (51, 29, 134, 44, 182)]
New lowest: tensor([[0.5714]]) | [(40, 20, 203, 121, 224), (161, 86, 78, 25, 215), (118, 58, 155, 59, 103), (35, 137, 174, 16, 114), (87, 138, 0, 54, 98), (170, 67, 125, 17, 231), (217, 157, 174, 225, 134), (117, 6, 216, 79, 30), (148, 12, 59, 116, 13), (29, 140, 75, 121, 149), (111, 8, 25, 110, 152), (208, 29, 204, 68, 94), (14, 15, 209, 32, 13), (209, 56, 141, 100, 59), (179, 29, 146, 217, 183), (86, 114, 190, 84, 218), (193, 126, 254, 163, 43), (169, 87, 40, 233, 225), (1, 175, 158, 221, 197), (0, 208, 48, 69, 76), (221, 37, 4, 121, 80), (101, 130, 179, 61, 73), (117, 21, 237, 198, 79), (122, 184, 100, 11, 172), (117, 220, 43, 214, 123), (222, 7, 181, 96, 179), (124, 169, 147, 248, 214), (138, 105, 243, 222, 55), (137, 64, 121, 131, 16), (18, 1, 109, 207, 105)]
New lowest: tensor([[0.5628]]) | [(182, 90, 156, 119, 223), (91, 171, 40, 87, 112), (187, 8, 70, 227, 251), (152, 161, 29, 210, 232), (149, 156, 184, 12, 173), (163, 142, 228, 149, 106), (41, 140, 87, 50, 59), (166, 1, 152, 171, 255), (86, 199, 163, 109, 112), (108, 223, 129, 32, 165), (175, 102, 167, 179, 147), (223, 174, 235, 181, 21), (18, 220, 147, 153, 81), (152, 187, 26, 250, 68), (15, 193, 100, 41, 199), (161, 218, 83, 118, 48), (58, 195, 113, 155, 226), (23, 96, 190, 106, 90), (84, 168, 168, 220, 231), (2, 199, 59, 4, 217), (159, 124, 197, 1, 247), (221, 25, 83, 83, 34), (1, 43, 211, 145, 168), (14, 112, 47, 127, 143), (55, 145, 96, 82, 124), (169, 44, 240, 127, 117), (16, 84, 179, 126, 36), (3, 100, 140, 63, 134), (156, 151, 236, 33, 104), (74, 189, 132, 228, 69)]
New lowest: tensor([[0.5590]]) | [(136, 51, 188, 199, 249), (27, 81, 42, 113, 172), (46, 122, 64, 245, 128), (66, 194, 226, 109, 132), (211, 124, 39, 115, 227), (27, 74, 86, 181, 32), (7, 44, 76, 180, 218), (15, 220, 25, 151, 56), (138, 176, 247, 47, 114), (51, 203, 24, 252, 210), (33, 152, 183, 180, 134), (60, 211, 186, 57, 0), (203, 134, 174, 223, 153), (35, 15, 134, 217, 76), (169, 96, 68, 190, 125), (8, 83, 167, 110, 127), (181, 14, 35, 237, 67), (49, 71, 238, 242, 132), (120, 177, 234, 145, 248), (26, 34, 170, 103, 6), (1, 197, 62, 121, 145), (124, 13, 147, 91, 180), (106, 107, 128, 112, 160), (43, 69, 15, 183, 119), (170, 169, 69, 205, 95), (54, 109, 161, 227, 178), (126, 188, 70, 143, 102), (27, 44, 7, 117, 193), (51, 204, 123, 39, 233), (49, 206, 216, 175, 227)]New lowest: tensor([[0.5576]]) | [(13, 220, 191, 38, 104), (14, 42, 131, 129, 11), (197, 146, 223, 106, 212), (50, 218, 245, 169, 55), (173, 209, 146, 233, 49), (197, 112, 102, 200, 226), (148, 146, 6, 225, 75), (13, 114, 50, 142, 61), (157, 72, 72, 192, 9), (162, 137, 57, 240, 169), (131, 131, 115, 226, 240), (133, 33, 187, 202, 56), (107, 43, 192, 122, 226), (10, 123, 81, 47, 19), (81, 68, 184, 251, 60), (200, 102, 90, 207, 246), (92, 52, 57, 154, 174), (58, 38, 9, 172, 242), (126, 159, 10, 25, 9), (32, 141, 225, 89, 155), (18, 138, 113, 128, 238), (81, 115, 130, 95, 16), (91, 139, 132, 214, 223), (14, 204, 83, 203, 115), (63, 68, 239, 195, 149), (133, 90, 94, 33, 39), (222, 154, 119, 70, 219), (132, 175, 209, 166, 241), (201, 69, 238, 80, 40), (221, 51, 152, 77, 139)]
New lowest: tensor([[0.5566]]) | [(65, 121, 250, 176, 193), (98, 110, 112, 225, 157), (66, 170, 220, 82, 218), (208, 189, 232, 14, 155), (149, 45, 86, 43, 252), (164, 26, 237, 60, 206), (209, 49, 213, 107, 92), (148, 23, 37, 238, 68), (132, 200, 146, 147, 63), (75, 176, 15, 230, 193), (190, 129, 104, 212, 218), (22, 202, 86, 118, 217), (101, 208, 115, 107, 75), (162, 78, 191, 208, 8), (8, 136, 139, 244, 110), (203, 183, 82, 192, 173), (162, 190, 95, 32, 165), (131, 113, 41, 228, 212), (151, 7, 145, 164, 240), (190, 33, 74, 210, 63), (195, 88, 175, 200, 200), (171, 48, 40, 97, 138), (213, 102, 20, 198, 178), (58, 58, 49, 180, 218), (200, 91, 179, 231, 108), (214, 115, 103, 196, 178), (194, 75, 98, 196, 178), (194, 85, 135, 252, 119), (190, 67, 29, 97, 98), (91, 94, 145, 186, 249)]
New lowest: tensor([[0.5557]]) | [(55, 118, 19, 14, 8), (176, 218, 69, 153, 26), (174, 3, 142, 74, 55), (23, 92, 229, 7, 67), (167, 79, 32, 52, 60), (4, 77, 71, 197, 9), (110, 222, 162, 51, 237), (182, 134, 146, 244, 133), (168, 2, 206, 40, 227), (84, 200, 246, 100, 15), (73, 203, 141, 138, 0), (202, 186, 170, 244, 205), (44, 55, 35, 149, 206), (61, 170, 122, 19, 121), (24, 165, 138, 20, 246), (132, 160, 183, 139, 31), (198, 204, 149, 215, 161), (168, 182, 131, 254, 160), (166, 115, 176, 55, 60), (202, 171, 47, 236, 147), (78, 19, 69, 127, 44), (3, 97, 192, 145, 11), (123, 59, 69, 33, 214), (46, 89, 42, 186, 82), (37, 179, 239, 49, 241), (220, 212, 253, 106, 178), (156, 69, 164, 125, 174), (123, 41, 60, 252, 219), (156, 210, 160, 189, 193), (93, 63, 6, 97, 94)]
It looks like it made some solid progress. The answer is not nearly this easy. Let’s let this run in the background while we try a solution with a bit more complexity.
Let’s abstract away the whole ML model portion of this challenge. Our goal is to minimize the value of f(x), f being the function of running the input through the model, and x being the pixels we pass change. We have a couple different options at our disposal, one of them being a technique called Gradient Ascent/Descent. The basic math works out like this:
Given a curve f(x), if your goal is to minimize the value of f(x), one of the options is to look at the derivative of the point that you are at on the curve. In other words, you look at the slope. The common explanation is if you are trying to ascend to a peak of the mountain, you could likely get pretty close by just going up hill. In the case of descending, think about a ball rolling down a curve following gravity:
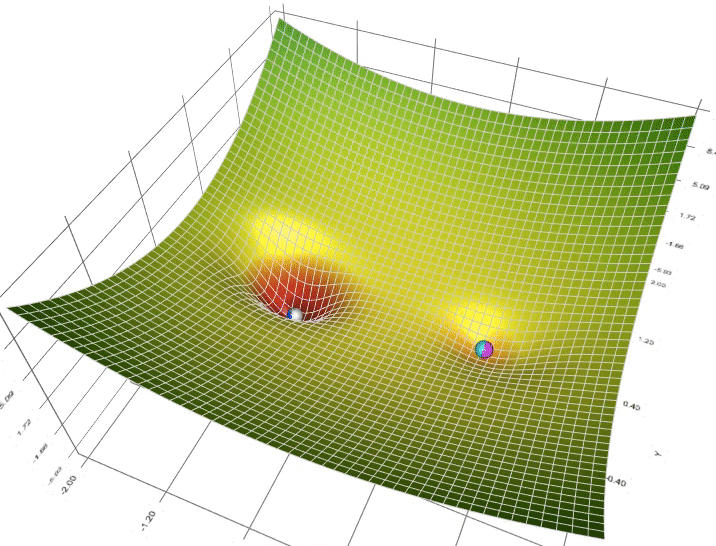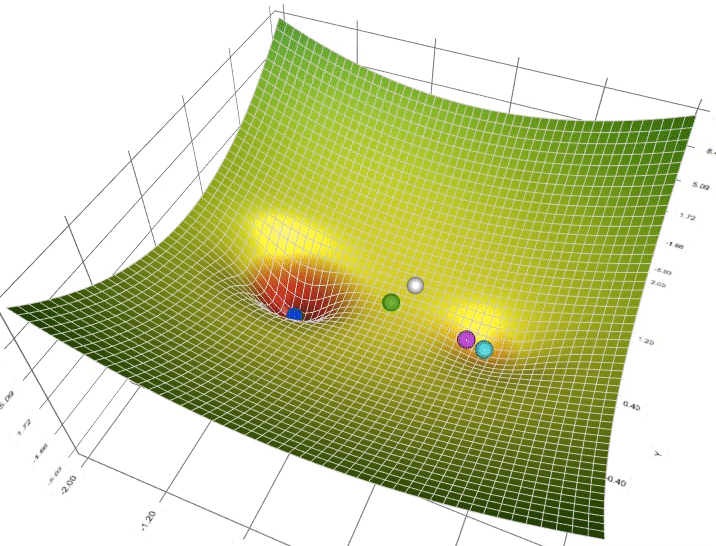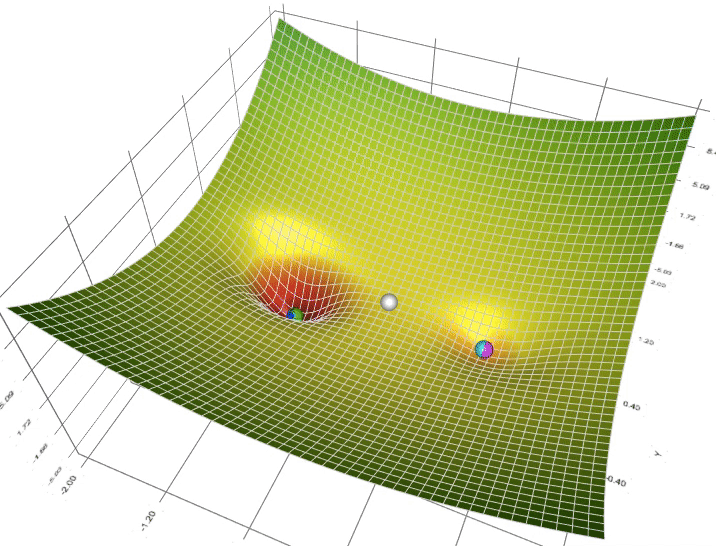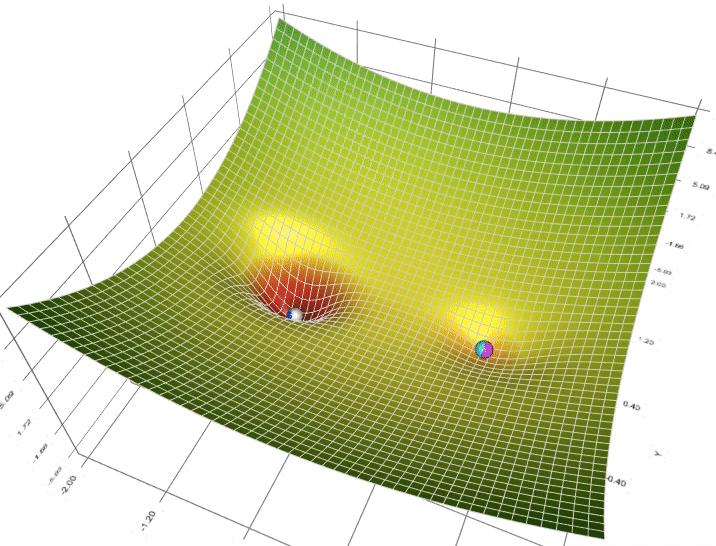
In this gif, we see that some of the balls make it to what we call a “Local minimum” rather than the “Global minimum”, which could be a problem, but we can burn that bridge when we get to it.
The trick is, rather than operating in 2 or 3 dimensions (pictured above), using gradient ascent would require 151 dimensions (!!!). This is because each one of the five values for the pixel would be assigned a dimension, resulting in 5 * 30 = 150 inputs, with the 151st being the resulting f(x) dimension. I did a lot of reading, but I couldn’t find any clean python examples that I could abstract to an arbitrary number of dimensions, though it was 2 AM at this point, and I just got done enjoying 2 Double Doubles and some cheese fries from the In-n-Out in Orem, so the perfect blog post or paper probably exists somewhere. Nonetheless, here is some of the resources I consulted:
I started poking around for more options, including a technique called “Fast Gradient Sign Method” or FGSM, most clearly illustrated in this tensorflow.org post:

But it requires the gradient vector, symbolized by that upside-down delta which runs into the same issue that I didn’t want to deal with earlier. I then read about “Genetic Algorithms”, a concept that pops up in a lot of “AI learns how to play X game” videos on Youtube. The basic idea is that there are a group of “agents” with varying characteristics that are passed into a function. Based on the scoring, an agent could be selected to be “reproduce”. The algorithm will then cull all but the highest performing agents, mutate their characteristics, sometimes swap some agents characteristics to mimic sexual reproduction, and run the test again This algorithm is pretty old, with implementations of it being dated back to this 1963 paper by Dr. Nils Aall Barricelli, from before we decided that field-defining research could only be done by people with lame sounding names. The goal is that over time, the population of agents will get better at the job of increasing the value of the scoring function.
We can apply this by:
- Create a bunch of agents, each storing a list of changed pixels
- We then need to design a scoring function that will increase as the result passing the altered image through the given model decreases.
- We score each agent, select the best agents, and mutate the list of changed pixels.
- Repeat step 3 until the score
yis less than 0.5. Step 1 and 2 are pretty easy, but 3 and 4 seem like a lot of work, so I turned to PyGAD, a Python library for genetic algorithms.
After a whole bunch of reading, I created this script:
#!/usr/bin/env python3
from math import floor
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
from torchvision.models import resnet18
from random import randint
import pygad
# Load up model
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 1)
model.load_state_dict(torch.load('model.pt'))
original = np.array(Image.open("worm.png"))
def random_mods():
mods = []
for _ in range(30):
x = randint(0, 223)
y = randint(0, 223)
r = randint(0, 255)
g = randint(0, 255)
b = randint(0, 255)
mods.append([x, y, r, g, b])
return mods
def unflatten(flat_mods: list):
assert len(flat_mods) % 5 == 0
mods = []
for i in range(len(flat_mods) // 5):
mod = [
flat_mods[(i * 5) + 0],
flat_mods[(i * 5) + 1],
flat_mods[(i * 5) + 2],
flat_mods[(i * 5) + 3],
flat_mods[(i * 5) + 4]
]
mods.append(mod)
return mods
def score(mods):
modified = original.copy()
mods = unflatten(mods)
for mod in mods:
x = floor(mod[0] * 224)
y = floor(mod[1] * 224)
r = floor(mod[2] * 256)
g = floor(mod[3] * 256)
b = floor(mod[4] * 256)
modified[y, x] = [r, g, b]
x = torch.tensor(modified.transpose(2, 0, 1) / 255.0, dtype=torch.float32).unsqueeze(0)
with torch.no_grad():
y = torch.sigmoid(model(x))
return y
desired_y = 0.48
def fitness_func(ga_instance, solution, solution_idx):
y = score(solution)
fitness = float(1.0 / abs(y - desired_y))
return fitness
fitness_function = fitness_func
num_gens = 1000
num_parents_mating = 4
sol_per_pop = 8
num_pixels = 30
data_points_per_pixel = 5
num_genes = num_pixels * data_points_per_pixel
init_range_low = 0
init_range_high = 1
parent_selection_type = "sss"
keep_parents = 1
crossover_type = "single_point"
mutation_type = "random"
mutation_percent_genes = 10
x_y_bounds = np.arange(0, 224) / 224
r_g_b_bounds = np.arange(0, 256) / 256
gene_bounds = []
for _ in range(30):
gene_bounds.append(x_y_bounds)
gene_bounds.append(x_y_bounds)
gene_bounds.append(r_g_b_bounds)
gene_bounds.append(r_g_b_bounds)
gene_bounds.append(r_g_b_bounds)
ga_instance = pygad.GA(
num_generations=num_gens,
num_parents_mating=num_parents_mating,
fitness_func=fitness_function,
sol_per_pop=sol_per_pop,
num_genes=num_genes,
init_range_low=init_range_low,
init_range_high=init_range_high,
parent_selection_type=parent_selection_type,
keep_parents=keep_parents,
crossover_type=crossover_type,
mutation_type=mutation_type,
mutation_num_genes=1,
gene_space=gene_bounds
)
ga_instance.run()
ga_instance.save(filename="genetic")
solution, solution_fitness, solution_idx = ga_instance.best_solution()
print(f"Best solution: {solution}")
print(f"Fitness value: {solution_fitness}")
prediction = fitness_func(None, solution, None)
print(f"Predicted fitness using solution: {prediction}")
print(f"Score using solution: {score(solution)}")
We can see that its target for y is 0.48, defined by desired_y. That means the algorithm is continuously optimizing a population of agents that when run through the model, return close to that number.
Running this program takes something like 5 minutes on my mid range laptop, and 2 minutes on BYU’s Cybersecurity Research Lab hashcracking rig. Because the initial conditions are random, it’s not always guaranteed to work. Here’s an output that results in y being less than 0.5:
➜ attack_of_the_worm python3 genetic_playground.py /home/jakemull/.local/lib/python3.10/site-packages/pygad/pygad.py:1139: UserWarning: The 'delay_after_gen' parameter is deprecated starting from PyGAD 3.3.0. To delay or pause the evolution after each generation, assign a callback function/method to the 'on_generation' parameter to adds some time delay. warnings.warn("The 'delay_after_gen' parameter is deprecated starting from PyGAD
3.3.0. To delay or pause the evolution after each generation, assign a callback function/method to the 'on_generation' parameter to adds some time delay.") Best solution: [0.6205357142857143, 0.6964285714285714, 0.5390625, 0.6875, 0.30078125, 0.5535714285714286, 0.5535714285714286, 0.86328125, 0.66796875, 0.87890625, 0.8883928571428571, 0.8080357142857143, 0.94140625, 0.9609375, 0.12109375, 0.8526785714285714, 0.5089285714285714, 0.87109375, 0.28515625, 0.3828125, 0.8526785714285714, 0.9017857142857143, 0.8515625, 0.91796875, 0.01171875, 0.38392857142857145, 0.49107142857142855, 0.7578125, 0.2890625, 0.58984375, 0.9642857142857143, 0.6607142857142857, 0.125, 0.9609375, 0.41796875, 0.9598214285714286, 0.8258928571428571, 0.2265625, 0.96484375, 0.50390625, 0.41964285714285715, 0.59375, 0.38671875, 0.921875, 0.76171875, 0.7410714285714286, 0.044642857142857144, 0.72265625, 0.88671875, 0.71484375, 0.7589285714285714, 0.14732142857142858, 0.03125, 0.73046875, 0.97265625, 0.36607142857142855, 0.03571428571428571, 0.74609375, 0.2109375, 0.0625, 0.16517857142857142, 0.0625, 0.4765625, 0.99609375, 0.78125, 0.4330357142857143, 0.59375, 0.921875, 0.625, 0.4921875, 0.6116071428571429, 0.9375, 0.6875, 0.25390625, 0.8046875, 0.03571428571428571, 0.8928571428571429, 0.9375, 0.796875, 0.9765625, 0.7008928571428571, 0.84375, 0.51171875, 0.89453125, 0.72265625, 0.6607142857142857, 0.5178571428571429, 0.98046875, 0.90625, 0.83984375, 0.15625, 0.9419642857142857, 0.921875, 0.92578125, 0.875, 0.9598214285714286, 0.6919642857142857, 0.9375, 0.6328125, 0.71875, 0.39285714285714285, 0.47767857142857145, 0.57421875, 0.734375, 0.046875, 0.9910714285714286, 0.3080357142857143, 0.3984375, 0.01953125, 0.93359375, 0.65625, 0.65625, 0.1953125, 0.82421875, 0.87109375, 0.8258928571428571, 0.125, 0.76171875, 0.73046875, 0.890625, 0.8080357142857143, 0.5223214285714286, 0.2734375, 0.02734375, 0.296875, 0.6428571428571429, 0.16071428571428573, 0.21875, 0.90625, 0.01171875, 0.5535714285714286, 0.36607142857142855, 0.109375, 0.4453125, 0.2265625, 0.2857142857142857,
0.27232142857142855, 0.20703125, 0.97265625, 0.84765625, 0.8258928571428571, 0.008928571428571428, 0.890625, 0.5703125, 0.15625, 0.8125, 0.12946428571428573, 0.26171875, 0.84375, 0.8671875]
Fitness value: 138.7860107421875 Predicted fitness using solution: 138.7860107421875
Score using solution: tensor([[0.4872]])
The clock doesn’t seem to be correct, probably a result of WSL jank.
It’s worth noting that the random attempt was running for something like 12 hours, and only got to a lowest of 0.543 confidence.
We now need to turn this array into a string of format x,y,r,g,b;x,y,... to pass to the server. We can copy the output into this script to both test the inputs, and create a string to pass to the server:
#!/usr/local/bin/python
import sys
from math import floor
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
from torchvision.models import resnet18
from random import randint
model = resnet18()
model.fc = nn.Linear(model.fc.in_features, 1)
model.load_state_dict(torch.load("model.pt"))
original = np.array(Image.open("worm.png"))
def score(mods):
modified = original.copy()
mods = unflatten(mods)
for mod in mods:
x = floor(mod[0] * 224)
y = floor(mod[1] * 224)
r = floor(mod[2] * 256)
g = floor(mod[3] * 256)
b = floor(mod[4] * 256)
modified[y, x] = [r, g, b]
x = torch.tensor(
modified.transpose(2, 0, 1) / 255.0, dtype=torch.float32
).unsqueeze(0)
with torch.no_grad():
y = torch.sigmoid(model(x))
return y
def unflatten(flat_mods: list):
assert len(flat_mods) % 5 == 0
mods = []
for i in range(len(flat_mods) // 5):
mod = [
flat_mods[(i * 5) + 0],
flat_mods[(i * 5) + 1],
flat_mods[(i * 5) + 2],
flat_mods[(i * 5) + 3],
flat_mods[(i * 5) + 4],
]
mods.append(mod)
return mods
inputs = [ ] # Copy inputs here
mods = unflatten(inputs)
print(mods)
num_of_pixels = 30
for i in range(num_of_pixels):
mods[i][0] = str(round(mods[i][0] * 224))
mods[i][1] = str(round(mods[i][1] * 224))
mods[i][2] = str(round(mods[i][2] * 256))
mods[i][3] = str(round(mods[i][3] * 256))
mods[i][4] = str(round(mods[i][4] * 256))
print(score(inputs))
res = ""
for pixel in mods:
res += ",".join(pixel)
res += ";"
print(res)
Running this script returns:
➜ attack_of_the_worm python3 interpret_solve.py
[[0.6205357142857143, 0.6964285714285714, 0.5390625, 0.6875, 0.30078125], [0.5535714285714286, 0.5535714285714286, 0.86328125, 0.66796875, 0.87890625], [0.8883928571428571, 0.8080357142857143, 0.94140625, 0.9609375, 0.12109375], [0.8526785714285714, 0.5089285714285714, 0.87109375, 0.28515625, 0.3828125], [0.8526785714285714, 0.9017857142857143, 0.8515625, 0.91796875, 0.01171875], [0.38392857142857145, 0.49107142857142855, 0.7578125, 0.2890625, 0.58984375], [0.9642857142857143, 0.6607142857142857, 0.125, 0.9609375, 0.41796875], [0.9598214285714286, 0.8258928571428571, 0.2265625, 0.96484375, 0.50390625], [0.41964285714285715, 0.59375, 0.38671875, 0.921875, 0.76171875], [0.7410714285714286, 0.044642857142857144, 0.72265625, 0.88671875, 0.71484375], [0.7589285714285714, 0.14732142857142858, 0.03125, 0.73046875, 0.97265625], [0.36607142857142855, 0.03571428571428571, 0.74609375, 0.2109375, 0.0625], [0.16517857142857142, 0.0625, 0.4765625, 0.99609375, 0.78125], [0.4330357142857143, 0.59375, 0.921875, 0.625, 0.4921875], [0.6116071428571429, 0.9375, 0.6875, 0.25390625, 0.8046875], [0.03571428571428571, 0.8928571428571429, 0.9375, 0.796875, 0.9765625], [0.7008928571428571, 0.84375, 0.51171875, 0.89453125, 0.72265625], [0.6607142857142857, 0.5178571428571429, 0.98046875, 0.90625, 0.83984375], [0.15625, 0.9419642857142857, 0.921875, 0.92578125, 0.875], [0.9598214285714286, 0.6919642857142857, 0.9375, 0.6328125, 0.71875], [0.39285714285714285, 0.47767857142857145, 0.57421875, 0.734375, 0.046875], [0.9910714285714286, 0.3080357142857143, 0.3984375, 0.01953125, 0.93359375], [0.65625, 0.65625, 0.1953125, 0.82421875, 0.87109375], [0.8258928571428571, 0.125, 0.76171875, 0.73046875, 0.890625], [0.8080357142857143, 0.5223214285714286, 0.2734375, 0.02734375, 0.296875], [0.6428571428571429, 0.16071428571428573, 0.21875, 0.90625, 0.01171875], [0.5535714285714286, 0.36607142857142855, 0.109375, 0.4453125, 0.2265625], [0.2857142857142857, 0.27232142857142855, 0.20703125, 0.97265625, 0.84765625], [0.8258928571428571, 0.008928571428571428, 0.890625, 0.5703125, 0.15625], [0.8125, 0.12946428571428573, 0.26171875, 0.84375, 0.8671875]]
tensor([[0.4872]])
139,156,138,176,77;124,124,221,171,225;199,181,241,246,31;191,114,223,73,98;191,202,218,235,3;86,110,194,74,151;216,148,32,246,107;215,185,58,247,129;94,133,99,236,195;166,10,185,227,183;170,33,8,187,249;82,8,191,54,16;37,14,122,255,200;97,133,236,160,126;137,210,176,65,206;8,200,240,204,250;157,189,131,229,185;148,116,251,232,215;35,211,236,237,224;215,155,240,162,184;88,107,147,188,12;222,69,102,5,239;147,147,50,211,223;185,28,195,187,228;181,117,70,7,76;144,36,56,232,3;124,82,28,114,58;64,61,53,249,217;185,2,228,146,40;182,29,67,216,222;
➜ attack_of_the_worm
Copying that block of text after the tensor([[0.4872]]) line into the remote server gets the flag:
➜ attack_of_the_worm nc challs.umdctf.io 31774
proof of work:
curl -sSfL https://pwn.red/pow | sh -s s.AAAdTA==.woGhIKLrM9b/31+n5cP/qw==
solution: s.Qu+qQXpy6ki9db3DxToNqWTIFglCjauiV1Ej+eEBP2nlX0bwbO5ZyIL39Pig/1oVV86BiWKTlxL9d+8b3yc1Q9uMFAnDsiof5DsQWmuMzLk7D7JTEU+BKqlDGwCicPleyLAycz/bDYL8N6pkha+eiQ+6GkT6NQjUmqv5kPFqbeiqKAr8xOTsM7Nz+IGGXMlK8SrzALv/SD2W+grgsdwD6w==
Enter a list of pixels to change, in the format 'x,y,r,g,b;x,y,r,g,b;...':
139,156,138,176,77;124,124,221,171,225;199,181,241,246,31;191,114,223,73,98;191,202,218,235,3;86,110,194,74,151;216,148,32,246,107;215,185,58,247,129;94,133,99,236,195;166,10,185,227,183;170,33,8,187,249;82,8,191,54,16;37,14,122,255,200;97,133,236,160,126;137,210,176,65,206;8,200,240,204,250;157,189,131,229,185;148,116,251,232,215;35,211,236,237,224;215,155,240,162,184;88,107,147,188,12;222,69,102,5,239;147,147,50,211,223;185,28,195,187,228;181,117,70,7,76;144,36,56,232,3;124,82,28,114,58;64,61,53,249,217;185,2,228,146,40;182,29,67,216,222
LISAN AL GAIB
UMDCTF{spice_harvester_destroyed_sunglasses_emoji}
I really enjoyed this challenge. I will definitely build a challenge inspired by this challenge for the upcoming BYUCTF.
The application of this kind of attack has plenty of applications in today’s world where every silicon valley 26 year old is throwing AI next to a random word in the English language. Scrolling through USENIX Security 2023, there are multiple papers that deal with attacking models:
- “Security is not my field, I’m a stats guy”: A Qualitative Root Cause Analysis of Barriers to Adversarial Machine Learning Defenses in Industry
- Adversarial Training for Raw-Binary Malware Classifiers
- That Person Moves Like A Car: Misclassification Attack Detection for Autonomous Systems Using Spatiotemporal Consistency
The last paper (talk here) is the most relevant to this challenge, discussing defenses against adversarial patches for self-driving cars.
Here’s the files:
Also, the challenge author under the name segal sent this list of resources in the CTF discord last year, I consulted a few of them:
Resources
ml resources basics of how neural networks work: https://aegeorge42.github.io/ backpropagation: https://colah.github.io/posts/2015-08-Backprop/ large but great guide to neural nets all the way up to transformers: https://karpathy.ai/zero-to-hero.html more on backprop: https://neptune.ai/blog/backpropagation-algorithm-in-neural-networks-guide gradient descent: https://towardsdatascience.com/gradient-descent-explained-9b953fc0d2c convolutions: https://colah.github.io/posts/2014-07-Understanding-Convolutions/ more convolutions: https://www.youtube.com/watch?v=KuXjwB4LzSA more on convolutional neural nets: https://colah.github.io/posts/2014-07-Conv-Nets-Modular/ section “Optimization in Machine Learning and Data Analytics” has good info on some loss functions (Adam, SGD, RMSProp, etc…) https://optimization.cbe.cornell.edu/index.php?title=Main_Page some info on activation functions: https://towardsdatascience.com/a-comprehensive-guide-of-neural-networks-activation-functions-how-when-and-why-54d13506e4b8 practical digit identification from scratch with numpy (helps for understanding from ground up): https://towardsdatascience.com/mnist-handwritten-digits-classification-from-scratch-using-python-numpy-b08e401c4dab intro to rnns: https://machinelearningmastery.com/an-introduction-to-recurrent-neural-networks-and-the-math-that-powers-them/ lstms: https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21 more on rnns and lstms: https://www.turing.com/kb/comprehensive-guide-to-lstm-rnn practical checklist to training neural nets: http://karpathy.github.io/2019/04/25/recipe/ practical course on deep learning: https://course.fast.ai/ some info on classical ml: https://www.akkio.com/beginners-guide-to-machine-learning classical ml algorithms wiki: https://wiki.pathmind.com/machine-learning-algorithms more classical ml: https://monkeylearn.com/blog/machine-learning-algorithms/